


This post is written by our Full Stack and DevOps Engineer, dhilipsiva, who plays a vital role in assuring the performance that we guarantee to our customers.
What does Appknox do?
Appknox helps developers and enterprises to uncover and fix security loopholes in mobile applications.
Securing your app is as simple as submitting your store link / uploading your app. We scan for security vulnerabilities and report back to you with vulnerabilities.
Primary Languages
- Python & Shell for the Back-end
- CoffeeScript and LESS for Front-end
Our Stack
- Django
- MySQL
- RabbitMQ
- Celery
- Redis
- Memcached
- Varnish
- Nginx
- Ember
Architecture
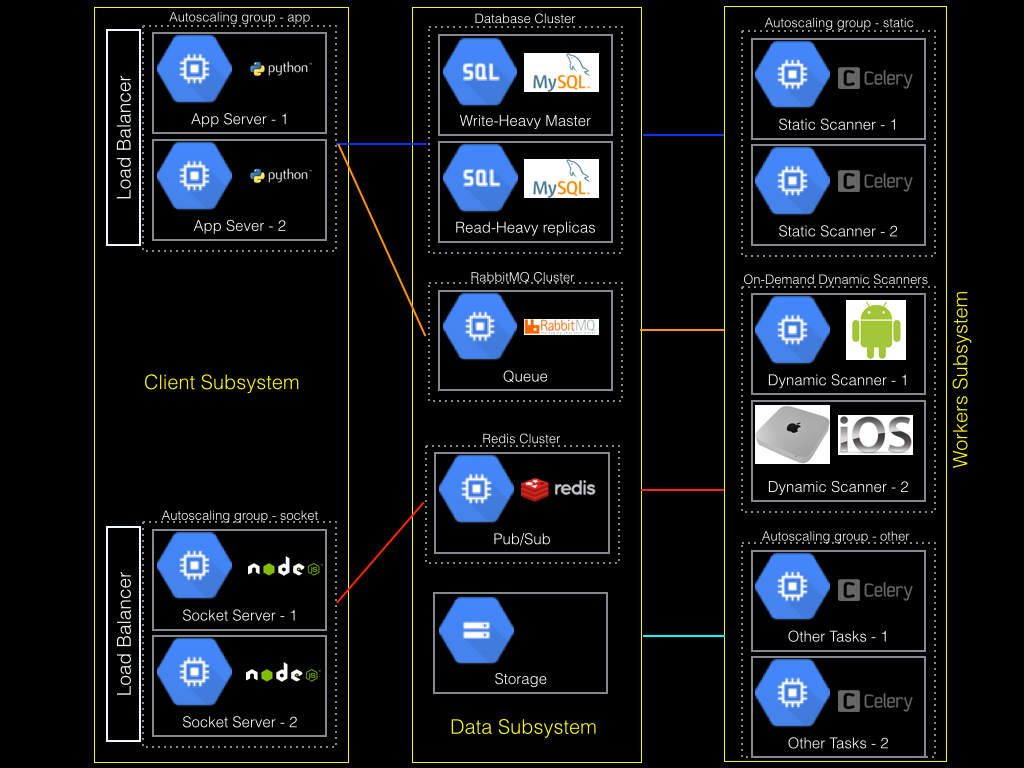
How it works?
Our back-end architecture consists of 3 subsystems: Client, Data and Workers.
Client Subsystem
The client subsystem consists of two different load-balanced, auto-scaling App & Socket Servers. This is where all user-interactions takes place. We took much care not to have any blocking calls here to ensure lowest possible latency.
App Server: Each App server is a single Compute unit loaded with Nginx and Django-gunicorn server, managed by supervisord. User requests are served here. When a user submits the url their app, we submit it to the RabbitMQ download queue and immediately let user know that the URL has been submitted. In case of uploading any app, a signed-url is fetched from server. The browser uploads data directly to the S3 with this signed-url and notifies the app server when it is done.
Socket server: Each socket server is a single compute unit loaded with Nginx and a node (socket-io) server. This server uses Redis as its adapter. And yes, of course, this is used for real-time updates.
Data subsystem
This system is used for data storage, queuing and pub/sub. Which is also responsible for a decoupled architecture.
Database Cluster: We use MySQL. It goes without saying that it consists of a Write-Heavy master and few Read-Heavy replicas.
RabbitMQ: A broker to our celery workers. We have different queues for different workers. Mainly download, validate, upload, analyse, report, mail and bot. The web server puts data into queue, the celery workers pick it up and run it.
Redis: This acts a adapters to socket-io servers. When ever we want to notify user an update from any of our workers, we publish it to Redis, which in turn will notify all users trough Socket.IO.
Worker Subsystem
This is where all the heavy lifting works are done. All the workers gets tasks from RabbitMQ and Published updates to users thorough Redis.
Static Scanners: This is an auto-scaling Compute unit group. Each unit consists of 4-5 celery workers. Each celery worker scans single app at a time.
Other tasks: This is an auto-scaling Compute unit group. Each unit consists of 4-5 celery workers which does various tasks like download apps from stores, generating report pdf, uploading report pdf, sending emails, etc.
Dynamic Scanning: This is platform-specific. Each Android dynamic scanner is a On-Demand Compute instance that has android emulator (With SDKs) and a script that captures data. This emulator is shown on a canvas in the browser for user to interact. Each iOS scanner is in a managed Mac-Mini farm that has scripts and simulators supporting the iOS platform.
Reasons for choosing the stack
We chose Python because the primary libraries that we use to scan applications is in python. Also, we love python more than any other languages that we know.
We chose Django because it embraces modularity.
Ember - We think that this is the most awesome Front-end framework that is out there. Yes, the learning curve is too steep than any-other, but once you climb that steep mountain, you will absolutely love ember. It is very opinionated. So as long as you stick to its conventions, you write less to do more.
And the rest are de-facto. MySQL because of relational data. RabbitMQ for Task Queues. Celery for Task Management. Redis for Pub/Sub. Memcached & Varnish for caching.
Things that didn't go as expected
One of the things that didn't go as expected is scaling sockets. We were using Django-socket.io initially. We realized that this couldn't be scaled to multiple servers. So we wrote that as a separate node module. We used node's socket-io library that supported Redis-adapter. Clients are connected to the node's socket server. So we now publish to Redis from our python code. Node will just push the notifications to clients. This can be scaled independently of the app-server that acts as a JSON endpoint to the clients.
Notable stuff about our stack
We love modular design. We went to modularize stuff so far that we de-coupled our front-end from our back-end. Yes, you read it right. All the HTML, CoffeeScript and LESS code is developed independently of the back-end. Front-end development does not require server to be running. We rely on front-end fixtures for fake data during development.
Our back-end is named Sherlock. We detect security vulnerabilities in mobile applications. So the name seemed apt. Sherlock is smart.
And our Front-end is named Irene. Remember Irene Adler? She is beautiful, colorful and tells our user's whats wrong.
And our Admin is named Hudson. Remember Mrs.Hudson? Sherlock's land-lady? Thinking of which we should have probably given a role to poor Dr.Watson. Maybe we will.
So Sherlock does not serve any HTML/CSS/JS files. I repeat, It does not serve ANY single static file / HTML file. Both sherlock and Irene are developed independently. Both have separate deployment process. Both have their own test-cases. We deploy sherlock to Compute instances and we deploy Irene to Google Cloud Storage.
The advantage of such architecture is that:
- The Front End team can work independent of the back-end without stepping on each other toes.
- The heavy lifting work like rendering pages on the server is taken off of server.
- We can open-source the front-end code. Making it easy to hire front-end guys. Just ask them to fix a bug in the repo and they are hired. After all, front-end code can be read by anyone even if you don't open-source it right?
Our deployment process
The code is auto-deployed from the master branch. We follow Vincent Driessen's Git branching model. Jenkins build commits to develop branch. If it succeeds we do another manual testing, just to be sure and merge it with master branch and it gets auto deployed.

 Gartner and G2 recommends Appknox | See how we can help you with a free Demo!
Gartner and G2 recommends Appknox | See how we can help you with a free Demo!
 Harshit Agarwal
Harshit Agarwal









_HighPerformer_HighPerformer.png)
_BestEstimatedROI_Roi.png)

